

La llegada de DeepSeek-V4-Pro no ha causado tanto revuelo como la que causó DeepSeek R1 hace un año y medio, pero puede que estemos ante un modelo aún más importante. Si aquella versión le descubrió al mundo que China estaba avanzando de forma espectacular en esta carrera, esta otra está comenzando a permitir vislumbrar otra cosa más interesante. Lo que ve la mayoría es un modelo muy decente y sobre todo "tirado de precio". Lo que esconde la empresa es otra cosa más importante: lograr la independencia de Nvidia y el hardware de EEUU.
Qué ha pasado. El pasado viernes los responsables de DeepSeek anunciaban algo sorprendente: su oferta promocional con un recorte de precio del 75% para usar su modelo DeepSeek-V4-Pro se mantendrá de forma permanente. Eso hace que este modelo, ofrezca prestaciones muy decentes (pero no excepcionales) por un precio realmente bajo:
|
1M tokens de entrada |
1M tokens salida |
|
|---|---|---|
|
DeepSeek-V4-Pro |
0,435 |
0,87 |
|
GPT-5.5 |
5 |
30 |
|
Opus 4.7 |
5 |
25 |
|
Gemini 3.5 Flash |
1,5 |
9 |
Bueno, bonito y muy barato. Es cierto que el rendimiento de DeepSeek-V4-Pro es inferior al de los modelos rivales de OpenAI, Anthropic o Google. Las pruebas de Artificial Analysis indican que el modelo de DeepSeek está a muy buen nivel, pero es además mucho más económico que sus competidores. Eso es especialmente relevante para tareas agénticas que consumen muchísimos tokens y que con este modelo se vuelven accesibles y muy asequibles.
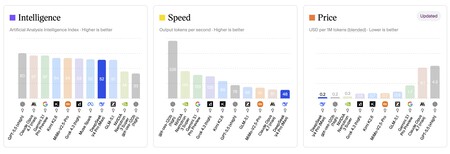 Según Artificial Analysis, DeepSeek se acerca al rendimiento de los mejores modelos de la industria, y aunque es más lento en sus respuestas, es también mucho más barato que los modelos frontera de OpenAI, Anthropic o Google.
Según Artificial Analysis, DeepSeek se acerca al rendimiento de los mejores modelos de la industria, y aunque es más lento en sus respuestas, es también mucho más barato que los modelos frontera de OpenAI, Anthropic o Google.
Una estrategia diferente. ¿Cómo va a ganar dinero esta empresa? No tiene planes de suscripción como su competencia local (GLM, Kimi) o la occidental (ChatGPT Plus, Claude Pro). Tampoco tiene modelos de voz o de imagen. No cuenta con un agente de IA para programación que compita con Claude Code. Publica los pesos abiertos de sus modelos y comparte sus innovaciones técnicas con la industria (y con sus competidores). Para quien sigue de cerca la empresa y estas decisiones la estrategia está clara. El objetivo de DeepSeek no es ganar la carrera de modelos de IA. Su objetivo es construir una industria china de hardware de IA que no dependa de Nvidia ni de TSMC... y cobrar su parte en ese proceso.
Independencia hardware. China tiene un problema estructural en esta carrera de la IA: las sanciones y vetos impuestos por EEUU hacen que no pueda acceder a los chips más avanzados ni a la fotolitografía UVE de ASML. Y como China no puede de momento competir en términos de capacidad de cómputo, lo que están haciendo sus empresas es lograr que sus modelos de IA necesiten menos capacidad de cómputo para lograr resultados similares.
Arquitecturas eficientes. Las arquitecturas Mixture of Experts (MoE) y Multi-head Latent Attention (MLA) son dos armas clave en esta estrategia. La primera ya existía pero fue adaptada por DeepSeek para su modelo: con ella solo se activan parte de los parámetros totales del modelo para responder la consulta sin perder precisión. Lo que hace MLA es comprimir la información de atención (la llamada KV Cache) con la que el modelo mantiene el contexto de una conversación, reduciéndola en un 90%. Ambas técnicas permiten reducir la necesidad de usar memorias HBM de alta velocidad, algo que es también llamativo de cara a desvelar la probable estrategia de DeepSeek.
La importancia de la KV Cache. Como explica el analista GDP en X, ese uso de MLA permite que para un millón de tokens, DeepSeek-V4-Pro solo necesite 5,48 GB de memoria HBM. Competidores como Zhipo AI, que desarrollan GLM 5, necesitan 60 GB para lo mismo, mientras que Qwen 3, de Alibaba, necesita 89 GB. Esta ventaja permite a DeepSeek ofrecer precios mucho más bajos para obtener rendimientos similares a los de su competencia, pero además hace que los modelos de DeepSeek puedan ejecutarse en chips de memoria chinos que no pueden competir en velocidad con módulos HBM.
Adiós HBM, hola NAND y SSD. Estas innovaciones abren la puerta al uso de memorias NAND e incluso unidades SSD para procesar estos datos, y ahí entra en escena YMTC, un fabricante chino de memorias Flash que se está convirtiendo poco a poco en un gigante global. También CXMT, que fabrica memorias DRAM, se convierte aquí en una alternativa y la razón es igualmente interesante: DeepSeek presentó un módulo de búsqueda de memoria en LLMs llamado Engram que está destinado también a evitar la excesiva dependencia de memorias HBM.

Cómo esquivar el monopolio CUDA. Nvidia sigue teniendo en CUDA un elemento fundamental para mantener su dominio del mercado, pero aquí DeepSeek también ha planteado una alternativa. Se llama Tile Kernels y se trata de unos núcleos software creados con TileLang (una variante de Python para este campo) que permiten gobernar chips de IA avanzados (GPUs).
Huawei como aliado invisible. Los responsables de Huawei indicaron recientemente que sus nuevos supernodos Ascend AI soportan completamente los modelos DeepSeek v4. Precisamente eso aporta otra ventaja fundamental a la empresa, que evita así (al menos en parte) la dependencia total de uso de chips de Nvidia y se prepara para poder fortalecer aún más la relevancia de Huawei en un mercado en que hasta hace poco la empresa de Jensen Huang era reina y señora.
Modelos abiertos para atraer a la industria hardware. Las empresas de EEUU siguen manteniendo sus modelos cerrados y propietarios, pero DeepSeek es una de las muchas startups chinas que los publican con pesos abiertos. Con ello lo que pretenden ella y las demás es no solo atraer a desarrolladores y usuarios de IA, sino crear un ecosistema hardware que adopte estas arquitecturas. DeepSeek invita a sus rivales a usar técnicas como MoE o MLA precisamente para que todos estos avances se conviertan en un estándar de facto y los fabricantes de hardware también los adopten e integren de forma optimizada en sus diseños.
Una ronda de 10.000 millones para avanzar. La empresa está además preparando una ronda de financiación en la que pretenden levantar 10.000 millones de dólares y con la que consiguirían una valoración de entre 45.000 y 50.000 millones de dólares. Aún lejos de las mastodónticas valoraciones de OpenAI o Anthropic (cercanas ya al billón de dólares) pero desde luego extraordinarias para una startup china. Con ese dinero tendrán muchas más opciones de seguir reforzando esta estrategia.
-
La noticia
DeepSeek es bueno, bonito y muy barato. Y sobre todo, el arma para crear una industria china de hardware independiente de Nvidia
fue publicada originalmente en
Xataka
por
Javier Pastor
.
🔥 Ver noticia completa en Xataka.com 🔥


